什么是负载均衡
当一台服务器的性能达到极限时,我们可以使用服务器集群来提高网站的整体性能。那么,在服务器集群中,需要有一台服务器充当调度者的角色,用户的所有请求都会首先由它接收,调度者再根据每台服务器的负载情况将请求分配给某一台后端服务器去处理。
那么在这个过程中,调度者如何合理分配任务,保证所有后端服务器都将性能充分发挥,从而保持服务器集群的整体性能最优,这就是负载均衡问题。
基本环境
三台centos虚拟机(windows也可以),都搭建好了nginx环境。当然也可以使用docker映射三个不同端口的nginx容器进行。centos使用docker搭建nginx环境方法:《使用docker快速搭建nginx+php环境》
三台主机分别是:
192.168.73.128 主
192.168.73.130
192.168.73.131
首先我们解析个域名codehui.net到主服务器192.168.73.128上
192.168.73.128 codehui.net
步骤
主服务器配置
编辑nginx配置文件
vi /etc/nginx/nginx.conf
在http节点中加入下面配置,负载均衡的几种常用方式查看文尾。
# 负载均衡服务器列表upstream codehui.net {server 192.168.73.130:80;server 192.168.73.131:80;}# 监听80端口的访问server{listen 80;server_name codehui.net;location / {proxy_pass http://codehui.net;}}
其他两台服务器配置
我们分别在两台服务器上新建个入口文件,作为区分
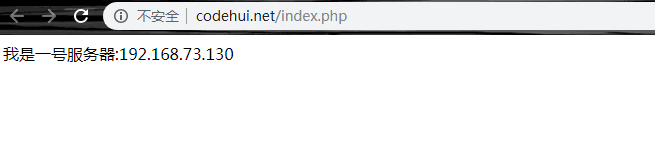
echo "<?php echo "我是一号服务器:192.168.73.130";" > index.php
echo "<?php echo "我是二号服务器:192.168.73.131";" > index.php
如果要配置其他功能,可以在nginx.conf中加入如下方法
server{listen 80;server_name codehui.net;root /usr/share/nginx/www;location / {index index.php index.html;}}
注意重启nginx服务
service nginx reload
测试
可以看到两次请求分发到了不同服务器

负载均衡的几种常用方式
1、 轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream nginx_server {server server1;server server1;}
2、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
upstream nginx_server {server server1 weight=4;server server2 weight=6;}
权重越高,在被访问的概率越大,如上例,分别是40%,60%。
3、 ip_hash
上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。
我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream nginx_server {ip_hash;server server1;server server2;}
4、 fair (第三方)
upstream nginx_server {server server1;server server2;fair;}
5、url_hash (第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
upstream backserver {server squid1:3128;server squid2:3128;hash $request_uri;hash_method crc32;}
每个设备的状态设置为:
- down 表示单前的server暂时不参与负载
- weight 默认为1.weight越大,负载的权重就越大
- max_fails:允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream模块定义的错误
- fail_timeout : max_fails次失败后,暂停的时间
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
配置实例:#user nobody;worker_processes 4;events {# 最大并发数worker_connections 1024;}http{# 待选服务器列表upstream myproject{# ip_hash指令,将同一用户引入同一服务器。ip_hash;server 125.219.42.4 fail_timeout=60s;server 172.31.2.183;}server{# 监听端口listen 80;# 根目录下location / {# 选择哪个服务器列表proxy_pass http://myproject;}}}

